Eine Verlinkung einer Seite ist wie die Empfehlung eines guten Italieners um die Ecke. Entgegen dem guten alten Backlink, scheint Google ein neues Verfahren zu verwenden: Brand Mentions. Wir erklären, wie Brand Mentions oder auch Implied Links genannt funktionieren, sowie welchen Wert sie heute für SEO haben.
Und: Wir zeigen, worauf Seitenbetreiber jetzt bei ihrer SEO-Strategie achten sollten.
Wir wollen in diesem Beitrag einige Fragen zum Thema Social Signals SEO klären und Ihnen effektive Tipps an die Hand geben, wie Sie Signale aus Sozialen Netzwerken für ihr Google Ranking arbeiten lassen.
Dass sich Shares, Likes und Kommentare irgendwie aufs Website-Ranking auswirken, ist kein Geheimnis. Dennoch bleibt die Frage:
Durch die robots.txt bzw. meta robots tags hat ein Webmaster eine wichtige Möglichkeit zur Hand, das Crawling auf der Webseite zu steuern. Es können Zugriffoptionen auf Seiten festgelegt und dadurch die Indexierung von Webseiten beeinflusst werden. Zudem kann festgelegt werden, ob Links verfolgt und gewertet werden oder nicht. Ziel ist es, nur relevante HTML Seite im Index der Suchmaschine zu platzieren.
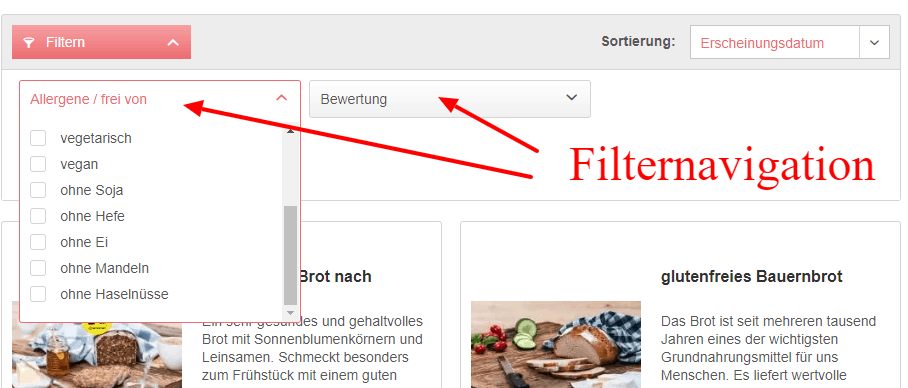
URL Parameter sind Informationen, die in der URL platziert und immer nach einem Fragezeichen auftauchen.
Ein Beispiel hierfür wäre: www.domain.de/schuhe?type=sneakers.
Unzählige Webseiten verwenden Parameter, die meisten sind Shops, die Filternavigation einsetzen, um wie hier im Beispiel Brote mit bestimmten Eigenschaften herauszufiltern.
Die angezeigt URL ist: https://www.panista.de/glutenfreies-brot
Klicke ich dann aber auf den Filter „vegan“, verändert sich die URL so:
Soweit so gut, aber Parameter in URLs verursachen auch Probleme. Denn mit jedem Filter-Parameter erhöhen sich die Anzahl an URLs – und da schrillen die Alarmglocken bei jedem SEO.
Brotkrümelnavigation, Brotkrumennavigation oder zumeist die englische Übersetzung „Breadcrumbs“, hilft Google-Bots die Websitehierarchie besser zu verstehen. Doch nicht nur den Bots bietet das Einbinden der Navigations-Hilfe einen echten Mehrwert.
So wie einst Hänsel und Gretel auf dem Weg in den Wald Brotkrümel verteilten, um den Weg aus dem Wald wiederzufinden, erfüllen Breadcrumbs die gleiche Funktion: Sie erleichtern die Navigation und es dem User seinen aktuellen Ort auf der Website besser zu verstehen.
Wir verwenden Cookies und andere Technologien auf unserer Website. Einige von ihnen sind essenziell, während andere uns helfen, diese Website und Ihre Erfahrung zu verbessern. Personenbezogene Daten können verarbeitet werden (z. B. IP-Adressen), z. B. für personalisierte Anzeigen und Inhalte oder Anzeigen- und Inhaltsmessung. Weitere Informationen über die Verwendung Ihrer Daten finden Sie in unserer Datenschutzerklärung. Indem Sie auf „Alle akzeptieren“ klicken, stimmen Sie der Verwendung ALLER Cookies zu. Sie können jedoch die „Cookie-Einstellungen“ besuchen, um eine kontrollierte Einwilligung zu erteilen.
Diese Website verwendet Cookies, um Ihre Erfahrung zu verbessern, während Sie durch die Website navigieren. Von diesen werden die nach Bedarf kategorisierten Cookies in Ihrem Browser gespeichert, da sie für das Funktionieren der Grundfunktionen der Website unerlässlich sind. Wir verwenden auch Cookies von Drittanbietern, die uns helfen, zu analysieren und zu verstehen, wie Sie diese Website nutzen. Diese Cookies werden nur mit Ihrer Zustimmung in Ihrem Browser gespeichert. Sie haben auch die Möglichkeit, diese Cookies abzulehnen. Das Deaktivieren einiger dieser Cookies kann sich jedoch auf Ihr Surferlebnis auswirken.
Funktionale Cookies helfen dabei, bestimmte Funktionen auszuführen, wie z. B. das Teilen des Inhalts der Website auf Social-Media-Plattformen, das Sammeln von Rückmeldungen und andere Funktionen von Drittanbietern.
Performance-Cookies werden verwendet, um die wichtigsten Leistungsindizes der Website zu verstehen und zu analysieren, was dazu beiträgt, den Besuchern ein besseres Benutzererlebnis zu bieten.
Analytische Cookies werden verwendet, um zu verstehen, wie Besucher mit der Website interagieren. Diese Cookies helfen bei der Bereitstellung von Informationen zu Metriken wie Anzahl der Besucher, Absprungrate, Verkehrsquelle usw.
Werbe-Cookies werden verwendet, um Besuchern relevante Anzeigen und Marketingkampagnen bereitzustellen. Diese Cookies verfolgen Besucher über Websites hinweg und sammeln Informationen, um angepasste Anzeigen bereitzustellen.
Notwendige Cookies sind absolut notwendig, damit die Website ordnungsgemäß funktioniert. Diese Cookies gewährleisten anonym grundlegende Funktionalitäten und Sicherheitsmerkmale der Website.
Wöchentlich das Wichtigste aus
✓ SEO & SEA
✓ Influencer Marketing
✓ Webentwicklung
mit dem netzgefährten Newsletter. seonative ist Teil der netzgefährten.