Ein aktuelles Rankingproblem eines Kunden machte mich nach längerer Zeit wieder auf das Diagnosetool von Google aufmerksam. Mit der Funktion in den Webmaster Tools, welche unter dem Punkt „Crawling“ zu finden ist, kann man sich aufzeigen lassen, wie der Googlebot eine Seite sieht. Die Funktion „Abrufen“ gibt es schon länger, seit Mai 2014 können Seiten zusätzlich gerendert werden. Das bedeutet, man erhält ein Vorschaubild wie der Googlebot die Seite sieht und kann ggf. Unterschiede zur Sicht des Besuchers erkennen. Bei der Seite des Kunden gab es die Vermutung, dass Google nicht alle Inhalte der Seite lesen und verstehen konnte, da u.a. viel mit JavaScript gearbeitet wurde. Eine Prüfung mit „Abruf wie durch Google“ ergab folgendes Ergebnis:
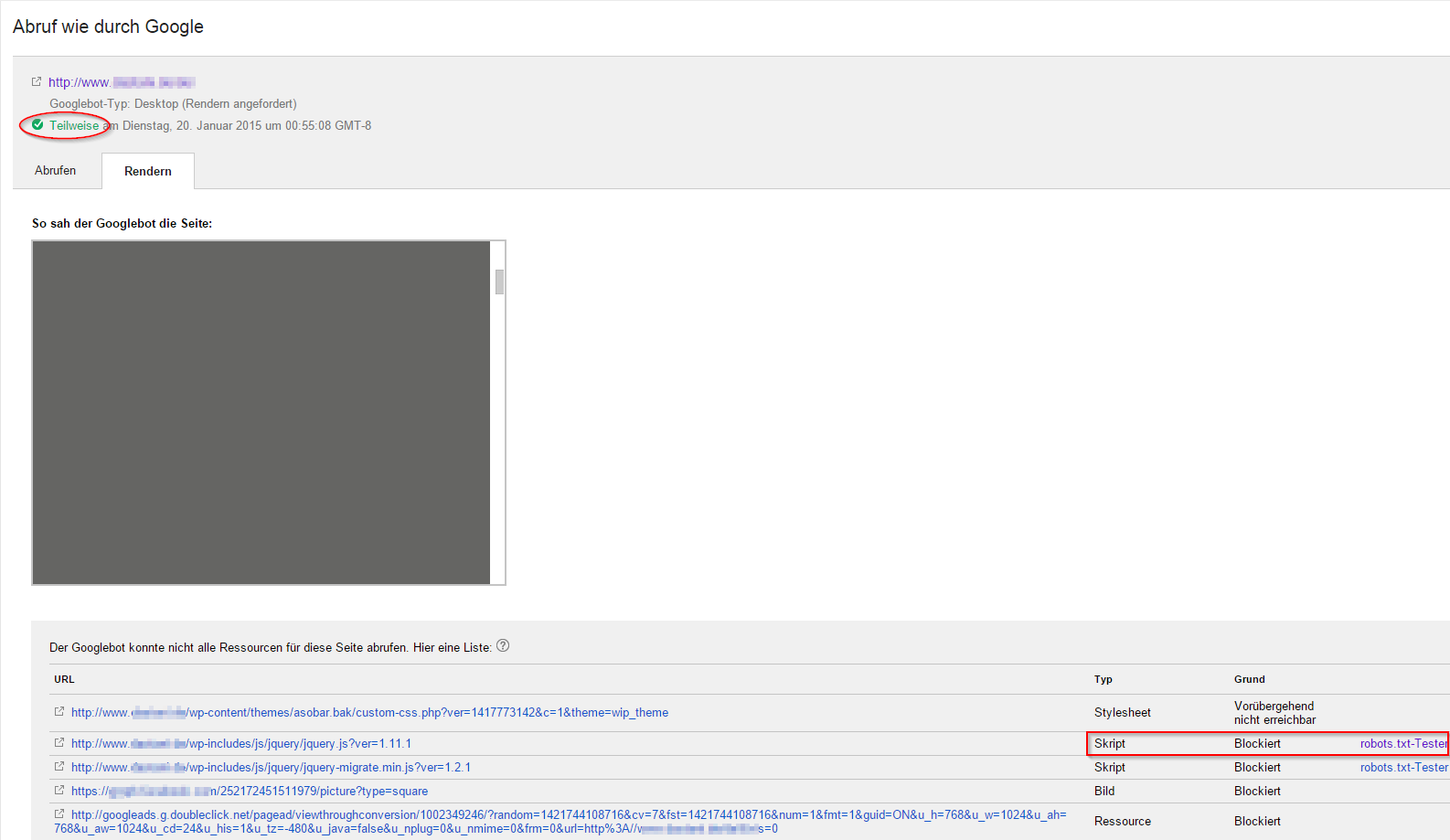
Der Googlebot konnte nicht alle Ressourcen der Seite erreichen, dementsprechend war das Vorschaubild nur eine graue Seite. Weiter unten wird aufgelistet, welche Ressourcen aus welchen Gründen nicht abgerufen werden konnten. Und siehe da, zwei Skripte wurden von der robots.txt-Datei blockiert. Doch haben gesperrte CSS- oder JavaScript-Dateien wirklich negative Auswirkungen auf das Ranking? In einem Blogpost empfiehlt Google:
“Wir empfehlen euch daher, dafür zu sorgen, dass der Googlebot auf alle eingebetteten Ressourcen zugreifen kann, die für die sichtbaren Inhalte oder das Layout eurer Website wichtig sind. Zum einen erleichtert euch das die Verwendung von “Abruf wie durch Google”, zum anderen kann der Googlebot dann diese Inhalte finden und indexieren.”
Nach kurzem Anruf beim Kunden wurden die blockierenden Elemente aus der robots.txt-Datei entfernt. Danach war das Rendern ohne Fehler möglich. Eine Woche später hat sich das Ranking von Seite 6 auf Seite 2 wieder erholt.
Was kann man mit der Funktion „Abruf wie durch Google“ noch anstellen?
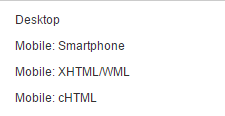
Zunächst kann man wählen, ob man die Startseite oder eine bestimmte Unterseite abrufen lässt. In der Woche stehen maximal 500 Abrufe zur Verfügung. Danach kann man den Googlebot-Typ auswählen. Hier gibt es folgende vier Browsertypen zur Auswahl:
Danach kann die Seite abgerufen werden (schnelle Variante) oder abgerufen und gerendert werden (eingehende Prüfung). Unterhalb erscheinen die Crawling-Ergebnisse, welche beispielsweise so aussehen können:

Wenn die Prüfung erfolgreich war, ist der Status „Abgeschlossen“. Weitere Statuswerte:
- Fehler: Ein Problem von Google (am besten erneut versuchen)
- Teilweise (bei Rendern): Google konnte nicht alle Ressourcen der URL erreichen
- Weitergeleitet: Der Server verwies Google während des Aufrufs an eine andere URL
- Blockiert: Ihre robots.txt-Datei blockiert das Abrufen der URL durch Google
Indexierung bei Google anfordern
Eine weitere nette Funktion ist das Senden von URLs an den Google Index. Kürzlich abgerufene Seiten können durch die Schaltfläche „An den Index senden“ direkt an Google gesendet werden. Danach öffnet sich ein Popup mit zwei Möglichkeiten:
- „Nur diese URL crawlen“: Google crawlt erneut die Seite und schickt diese anschließend an den Index (500 Abrufe pro Woche)
- „Diese URL und ihre direkten Links crawlen“: Die angegebene URL und die direkt verlinkten Seiten werden erneut gecrawlt. (10 Anfragen pro Monat)
Dadurch können z.B. neu erstellte Seiten manuell und schnell an den Index gesendet werden.
Das Tool bietet zusammenfassend umfangreiche Möglichkeiten rund um das Thema „Crawling und Indexierung“ und kann nicht nur bei Rankingproblemen hilfreich sein. 😉





